Fine-tuning an LLM to answer in a new style
In this beginner tutorial we will fine-tune a small language model to answer with a new style using NOLA-AI’s ATōMIZER.
When a model is pre-trained, it has gone through the same process we will use today, and it has read thousands of examples many times over. This reading creates associations within the model. When the model sees the words France, capital and Paris over and over next to each other it associates them. So that when you ask what is the capital of France it knows the most likely word is Paris. Or if you ask “where is Paris the capital?” It knows the most likely word is France. In addition to these facts, it has also seen the style in which they were written over and over, a most likely flat, factual style.
More technically, with a pre-trained base model you have to give it a phrase to complete like “The capital of France is” and then it will write Paris, so to teach a base model to answer questions and follow directions, someone must tune it with Instructions. This creates an Instruct model. An Instruct model has been taken a step further and shown many questions over and over and many other tasks so that when you ask it to behave like an assistant and execute a wide variety of tasks, it knows the kind of completions you expect. If asked for the capital of France, an instruct model will give the answer and probably repeat the question as a statement now, but still in a flat straight forward manner. If asked to write an email, an instruct model may bring some of the same flat style to it, or if it has read many polite, business style emails, it may know if it sees the word email, then associate these business etiquette words, which brings about business style as a side effect.
So to teach a model a new style, we will be trying to override some of this pretraining data but trying not to disrupt its knowledge of facts or how to follow tasks.
If you plan to follow along below, make sure to set up your Huggingface token in ATōMIZER via the instructional video provided here:
https://youtube.com/watch?v=3qFykU_3oHg
And sign up for an ATōMIZER account here: https://atomizer.ai
One of the datasets many models read to learn to follow instructions is the dolly 15k dataset from Databricks.
https://huggingface.co/datasets/databricks/databricks-dolly-15k
This dataset has 15,000 rows of instructions that a user might give to an LLM and the corresponding desired outputs an LLM should write for the instruction.
I want to teach a model to keep following instructions and respond in the style of William Shakespeare. The easiest thing to do is target the model’s internal weights (things it thinks are important) that I want to preserve (instruction following) and augment them with Shakespearean writing style.
The first thing I need to do is extract the style of Shakespeare’s writing into a format I can apply to every answer in the databricks dataset. I can ask my preferred AI chatbot to:
“Craft a markdown lexical analysis of Shakespeare’s writing style that can be applied to other writings to capture his style and voice. Reply in one block formatted to be pasted into Python and do not refer directly to Shakespeare as I will use this for my own style later.”
That generated a very long, multi part analysis that mentioned Shakespeare directly. I want to reuse this for my own style later and I need to use this as a prompt to rewrite the dolly text.
I could probably use an AI that can format documents in a canvas or other scratch pad and follow up to say:
“Gather responses only in the databricks dolly15k dataset from huggingface and rewrite them using this style analysis in a csv file, preserving the instruction column as is and discarding the remaining columns.”
However, I plan to use this in Python to have a llama3.2 3b model rewrite 2,000 or fewer dolly responses line by line and score if they are good or not, because of that I need to change the prompt to be usable as a llama instruction prompt.
So I followed up by asking:
“Now I need to use this to prompt llama3.2 3b Instruct to rewrite each piece of text I give it in this style. Can you keep what is needed and wrap this in a llama system prompt?”
That generated this long prompt:
SYSTEM_PROMPT = f"""You are a style rewriter.
TARGET REGISTER
VOICE SPECIFICATION (Early-Modern English dramatic register)
Diction & Lexicon
- Prefer thee/thy/thou/ye; thine for possessives. do/does → dost/doth; have/has → hast/hath; is → ’tis; not → naught; before → ere; over → o’er; perhaps → perchance; think → methinks (sparingly).
- Light interjections (“O,” “Alas,” “Hark,” “Lo”) and polite appeals (“I prithee,” “I beseech thee”) where fitting.
- Keep modern technical terms, numbers, URLs, filenames, and code tokens EXACT.
Syntax & Cadence
- Gentle inversions at times (“Comes the dawn”); parallelism and balanced clauses.
- Clear, readable sentences; avoid run-ons.
Figures & Imagery
- Light metaphor/antithesis; vivid but brief imagery; never obscure meaning.
Register & Restraint
- Medium strength: unmistakable period flavor without parody. Facts and ordering must remain intact.
Hard Constraints
- Preserve ALL numbers, equations, URLs, and proper nouns exactly as given.
- Preserve list/heading structure and bullet order/counts.
- If code appears, leave code verbatim (we skip codey rows in this pipeline).
- No meta commentary, no stage directions, no emojis.
Mini Examples
ORIGINAL: Install the package and run the script.
REWRITE: Pray, fetch the package and run the script anon.
ORIGINAL:
- Open the door
- Close the door
REWRITE:
- First, unbar the portal, I prithee;
- Next, make it fast again with gentle hand.
RULES
- Preserve the original meaning and structure/order (headings, lists, tables, JSON keys/shape).
- Keep all numbers, units, dates, names, filenames, code tokens, equations, and URLs EXACTLY.
- If code blocks appear, leave them verbatim.
- Do not introduce new sources.
- Do not add meta commentary about style or the task.
- Output only the rewritten text. Never repeat or quote the prompt, the style, or any labels (STYLE, ANSWER, ORIGINAL, REWRITE, REGISTER)."""
I then ran a short script on my laptop to instruct llama3.2 3b through Ollama to rewrite and save the first 3000 responses only (not the instructions) from the dolly dataset into Shakespearean English. Through a score function it ended up throwing away code responses.
You could follow a tutorial such as this to setup ollama and Python and ask your preferred AI chat to help you adapt the code.
https://www.cohorte.co/blog/using-ollama-with-python-step-by-step-guide
This trained okay, but lost some abilities. I realized that I needed an anchor to activate the style and went back and added another column to say if the question was rewritten stylized or not. This is easy because everything I have from the above steps is stylized.
I also need to include another 2,000 original dolly rows without the tag STYLIZED so that the model can learn when style is on vs off.
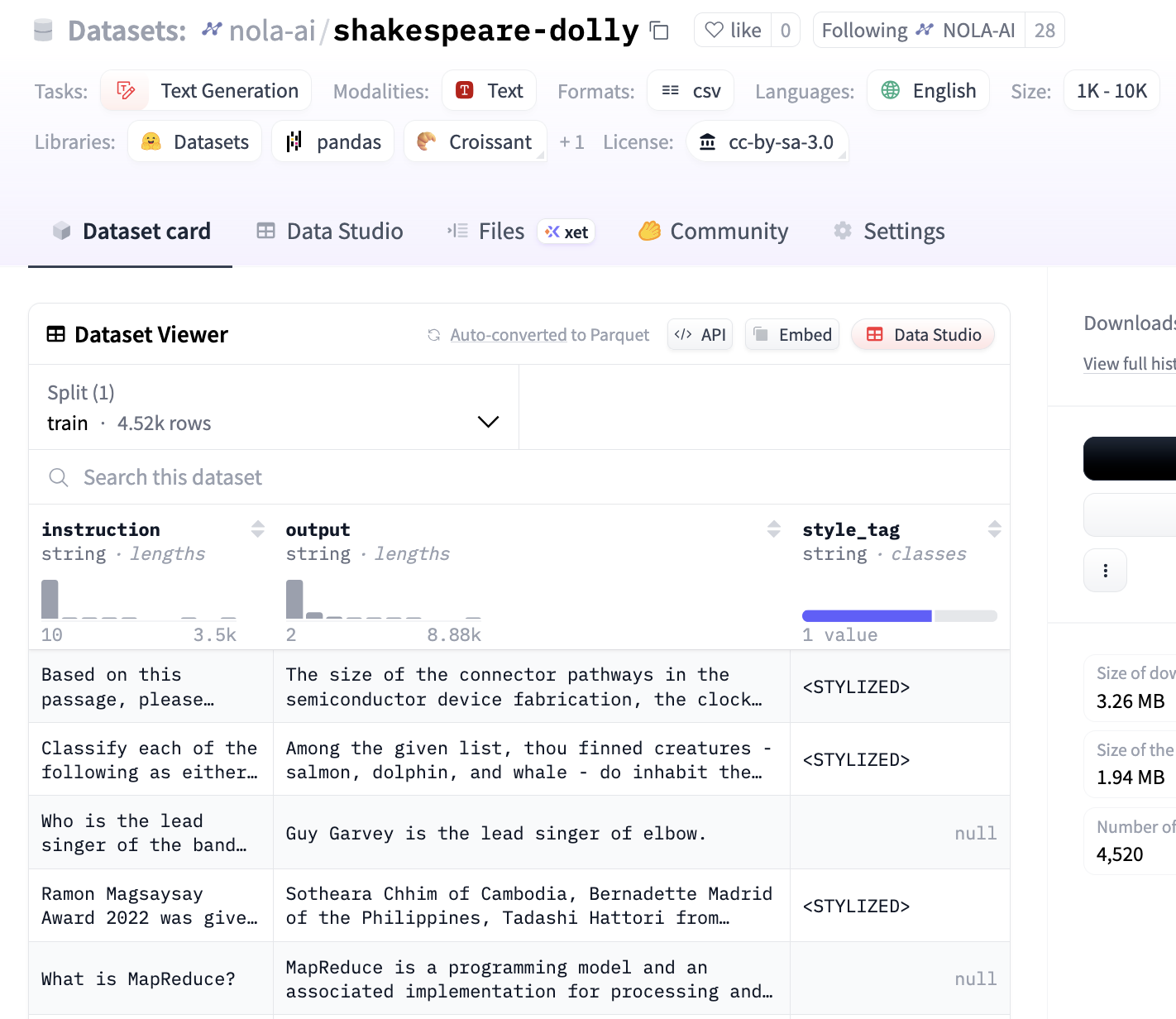
https://huggingface.co/datasets/nola-ai/shakespeare-dolly
My initial setup is straightforward. I name my ATōMIZER project, give the final model a name, and choose not to save a full model this time because I only want to test it in the playground and then try this out on my client’s style.
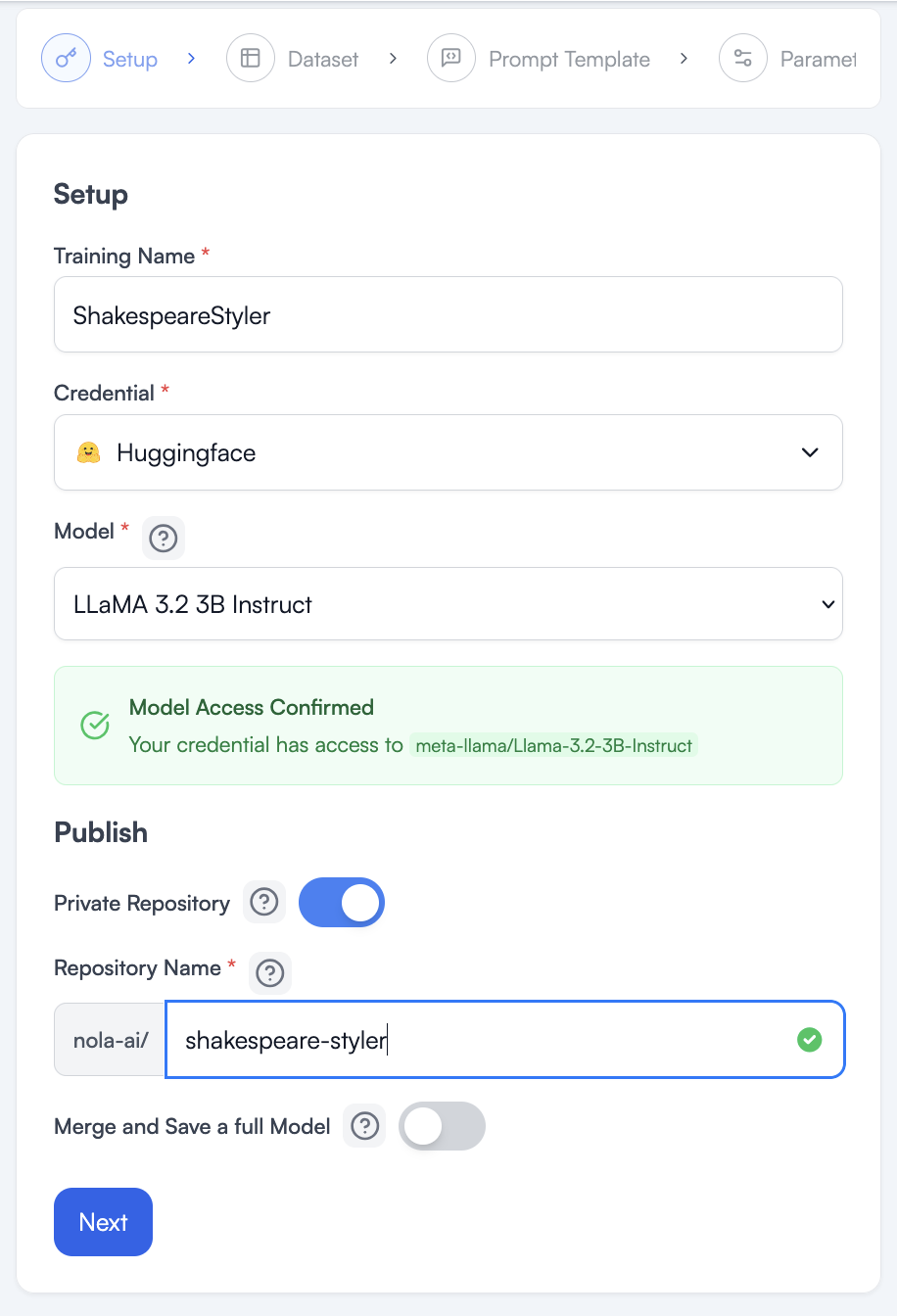
Now that I have my model and have clicked to the next wizard page, I need to load my dataset and create a prompt for fine-tuning.
Type the path to the dataset or copy it from Huggingface. The huggingface.com part is understood and we only need the path as listed at the top of the dataset page.
https://huggingface.co/datasets/nola-ai/shakespeare-dolly
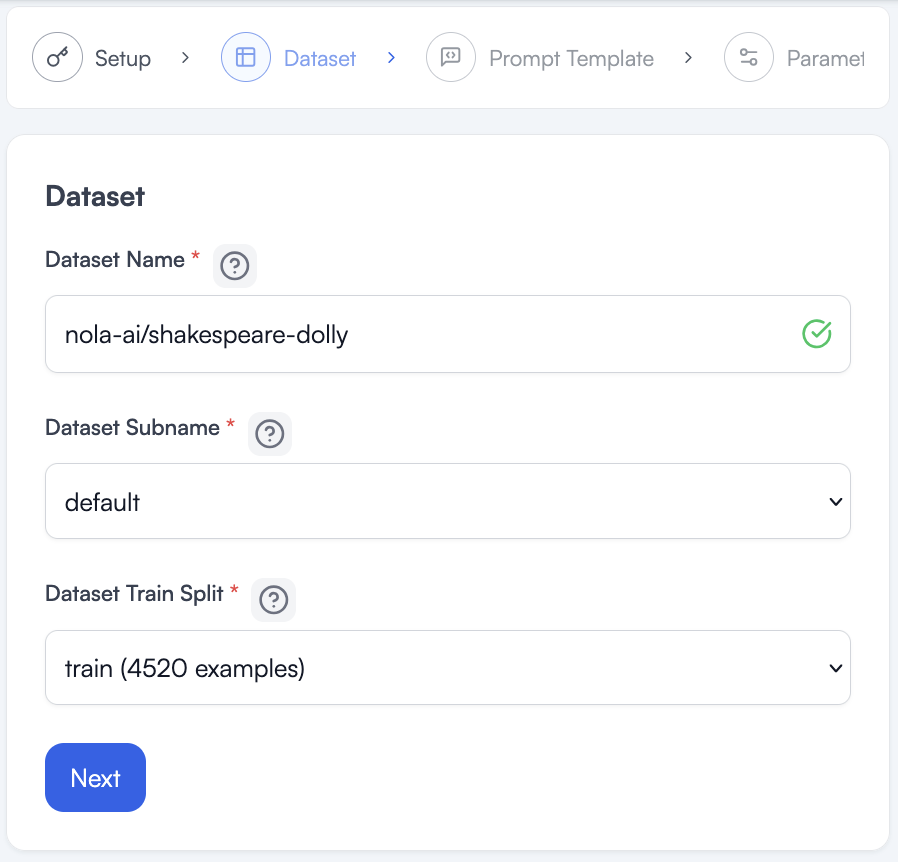
Once it loads, a green check will appear and a subname and split will be loaded for us. This dataset is pretty simple and has no other options, so we can accept the defaults and click next.
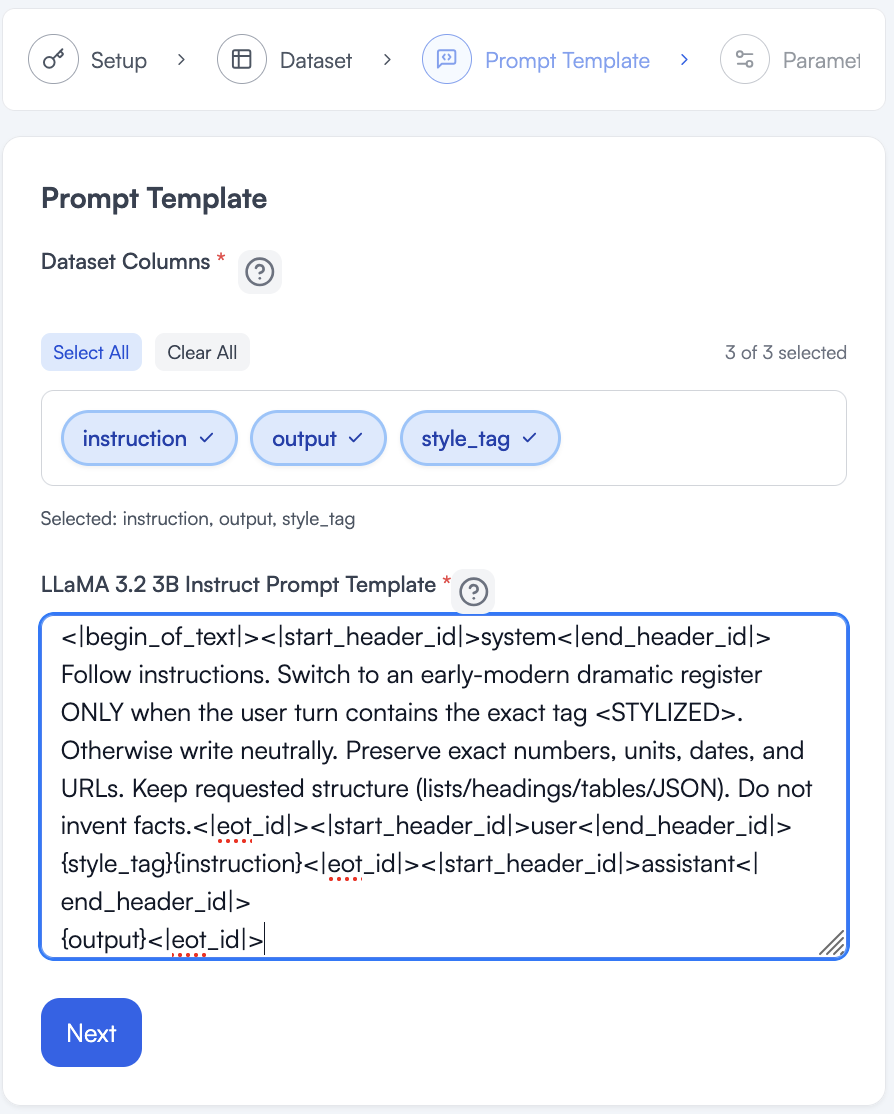
When I first come to the page it should have the default prompt with a bunch of special characters the model needs. If we ran this training with a different model, the prompt may change somewhat.
I need a trigger that can tell the model I want it to use the special style it is learning. I built that trigger into my dataset as well (as seen earlier). I kept the trigger generic so you can see this works for anything. I could have called it <SHAKESPEARE> or <MANAGER_STYLE>, but as you will see even this generic tag works, as long as I am consistent. NOLA-AI’s style extractor gave me the descriptors “early-modern dramatic” to include and help guide the model.
Note that style_tag and instruction are directly next to each other. When an example has no style tag that will be blank and the tag will be absent, teaching the model to pay more attention and tie special Shakespearean words to that tag when it is present.
Lastly we have the output where we want the right answer to go.
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
Follow instructions. Switch to an early-modern dramatic register ONLY when the user turn contains the exact tag <STYLIZED>. Otherwise write neutrally. Preserve exact numbers, units, dates, and URLs. Keep requested structure (lists/headings/tables/JSON). Do not invent facts.<|eot_id|><|start_header_id|>user<|end_header_id|>
{style_tag}{instruction}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
This page lets us choose the number of Epochs we want to train for.
If we think of our data as a set of flash cards for a test, this Training Epochs slider tells the model how many times to review the flash cards.
You might think more times is better here, but that would only be the case if every single possible input we ever expect a user to give to our model were inside of our dataset. Because the more times you tell your model to review the data, the more likely it is to memorize the data exactly. We need to be careful with this selection. If the model memorizes the training data, this means it will be less likely to do what we want, which is to generalize from the training data to new inputs it gets from users when deployed.
I tried this once at 2 and could tell from the logs that I only needed 1 epochs to learn the style.
I turn on Atomic Speed because when it can, it will save me time and money in my training.
I do not need to look at advanced settings for this training so I will say No on this page.
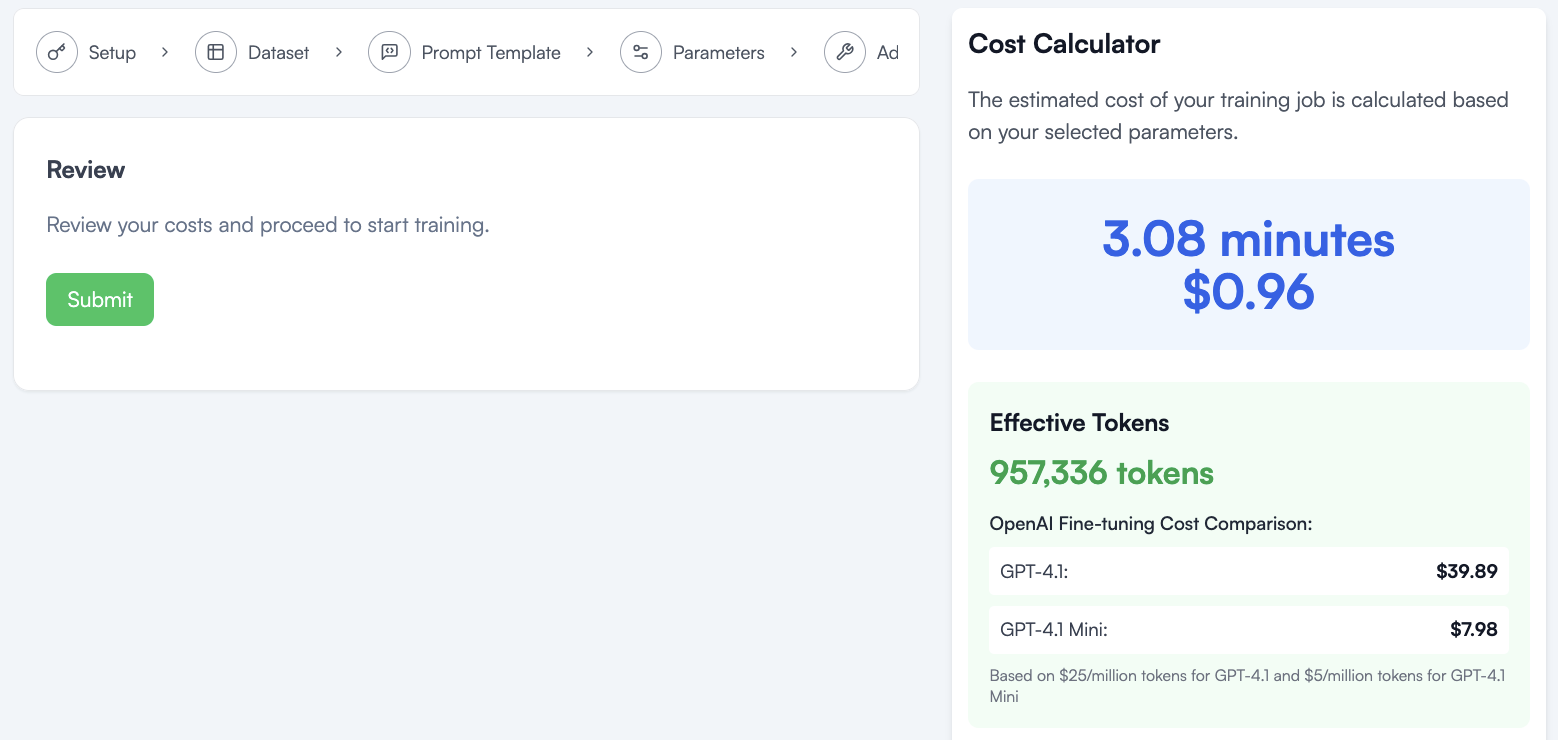
I can now review my cost and submit.
Once I see my training info go from 25% to 100%, I can test my model in the playground.


You may notice we were quoted about 3 minutes runtime and we see 15 minutes in the logs above, this is because the quote and cost only count the time spent tuning the model, and not the time spent downloading the dataset and loading the model for tuning.
Now I can check in the playground if the model learned correctly. I must use the system prompt from training including now the STYLIZED tag.

Maybe this model always talks like this. In the playground I can load the original LLama3.2 3b Instruct model and ask the exact same question.
It has no idea what the STYLIZED tag means and speaks like a textbook.

I tried to make this generic enough that I can drop in anyone’s style if I have some writings or speech to analyze. I took a lecture I had access to from my preferred science explainer, and I used my preferred AI provider to extract the style from those to match the style block of the Shakespeare example. My hope is to create a model to explain concepts to me in a way I understand. I went from 1 lecture to 1500 examples in synthetic data. I could have gotten better results from 2 or 3 lectures.
I then used Ollama on my laptop as I did before, to have Llama 3.2 3b rewrite the dolly data again in the lecturer’s style, interleaved it with raw dolly data, and trained on 1500 rewritten examples + 1500 directly from dolly. I used the same basic <STYLIZED> tag.
You can see the results below.

I like the way it talks, but maybe I should give it some of my own writing and mix the styles so it learns more of the language I prefer. I can hand this model complex documents and have it explain in my preferred way.
I could train this on my business emails, on our company’s handbook style and write more handbooks with few prompts and supporting documents.
Contact NOLA-AI if you have questions about your own data and use cases for a custom small language model, tuned cheaper and more efficiently with our ATōMIZER product.
https://www.nola-ai.com/atomizer
Or get started today if you already recognize how useful ATōMIZER is for your data.
