Note: there will be some anthropomorphizing of model behavior in the following explanation. This is not intended to be a scientific explanation but rather a walkthrough of how to imagine what the model is doing behind the scenes for new users uninterested in the actual math.
A model is taught by reviewing question and answer pairs in a dataset over and over. It compares its answer to the known answer and calculates how wrong it is, adjusts the importance of input words to output answers, and then moves on to the next pair. This amount by which it is wrong is called loss.
Suppose we want to teach a model a new behavior. It has learned words to associate with various countries as their capitals. But I want it to take the first capital letter and change the behavior it already knows. I will need to show it examples of the new behavior I want.
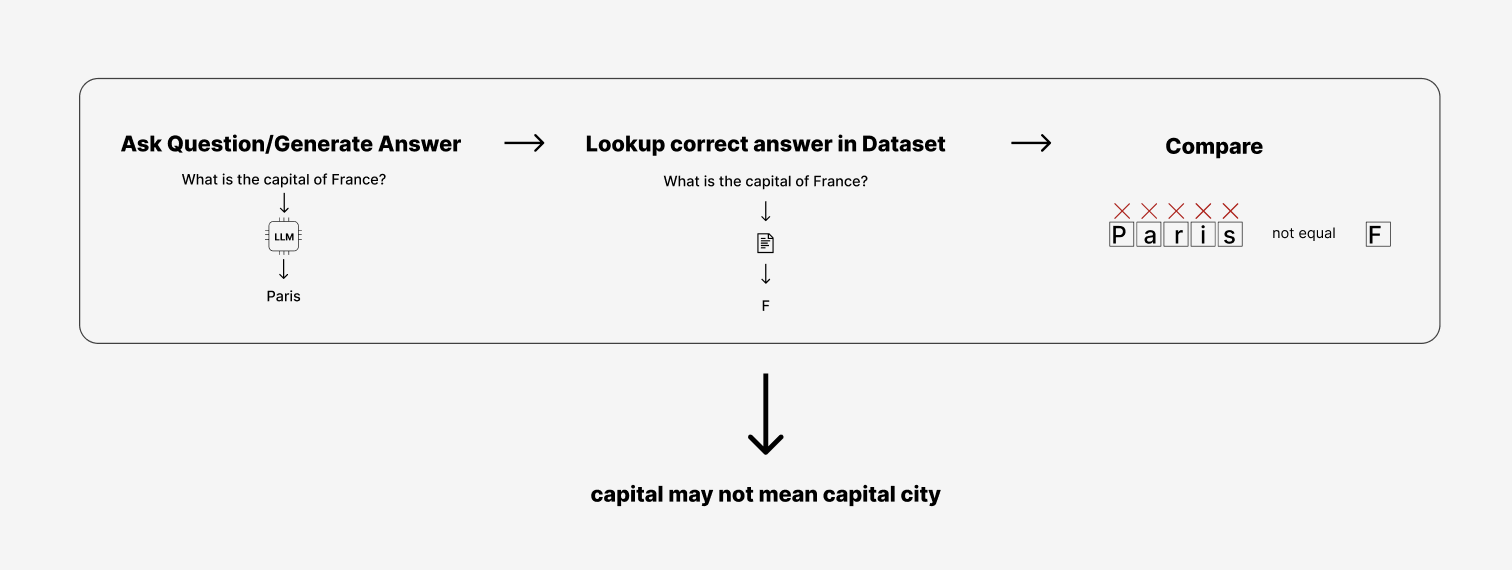
At the beginning of this training, if the first question it encounters is:
What is the capital of France?
It will say “Paris.”
Then it will check its answer against the training column for the new behavior and find the correct answers was supposed to be “F”.
Paris is not equal to F so it will calculate how wrong it is, adjust the importance of some words again, and then move on to the next input in the training dataset.
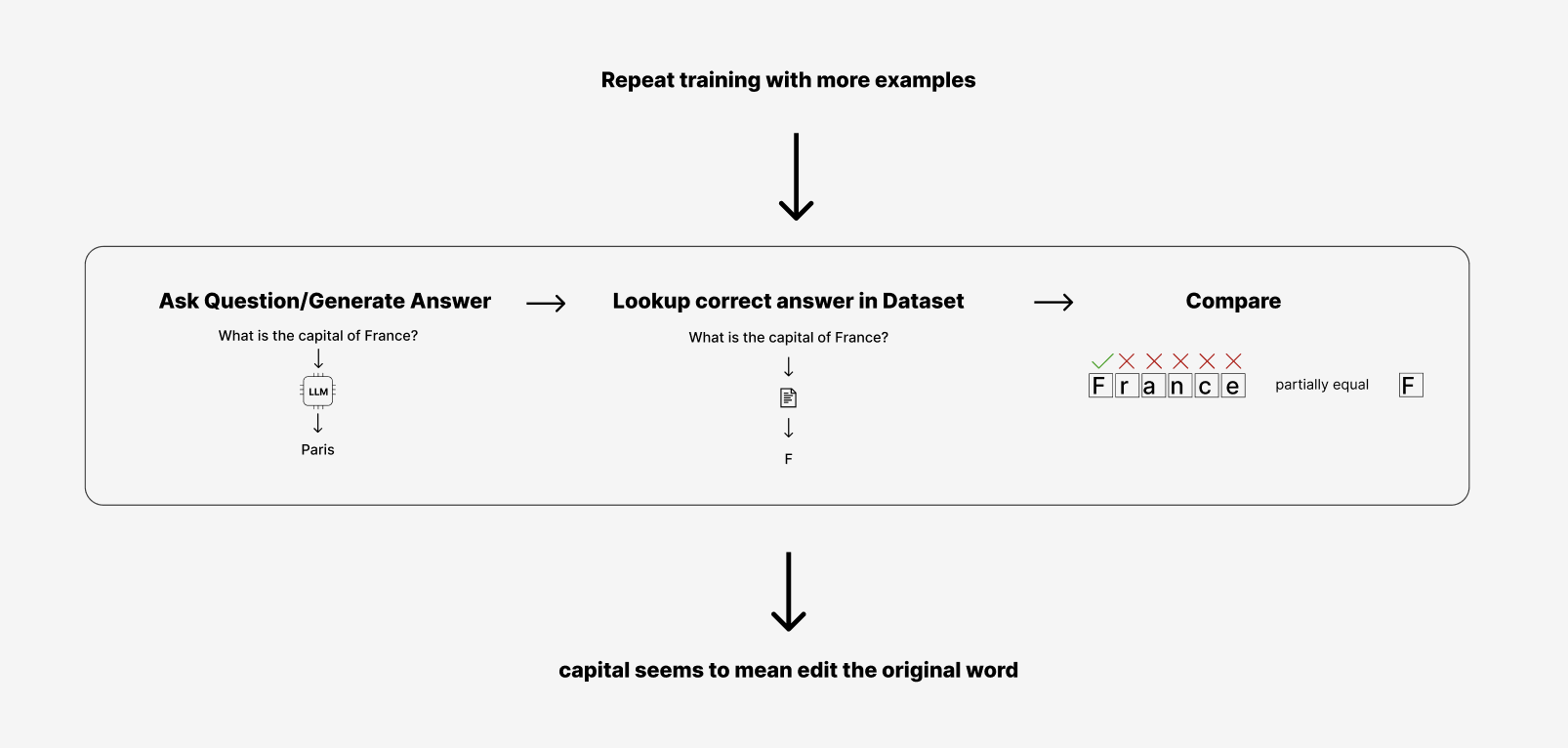
Imagine we do that about 1,000 times and then if we encountered that question again:
What is the capital of France?
The model will probably have adjusted how important capital is and how important the answer is. Even if it might be used to seeing the right answer come after this question, I have told it through 1,000 different steps to change the math about how it calculates the next best answer.
It will probably say “France”.
That seems quite wrong, but actually it is closer to correct. It knows the letter F is important, but it is still used to having to look up a whole word as the answer. France is not equal to F though, so it is marked as wrong, but it is wrong by a smaller amount than it was in the first example, so it is getting closer. The loss is lower than before.
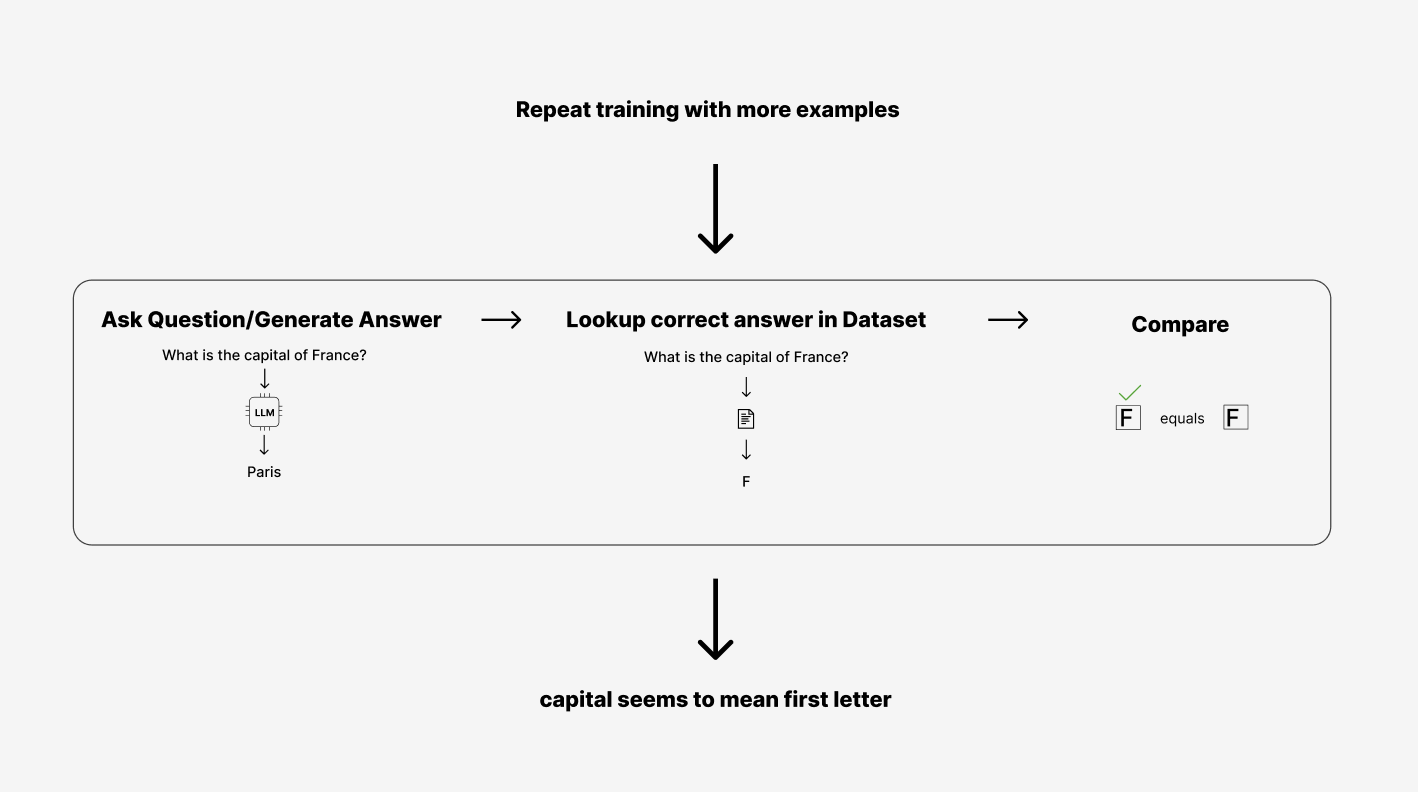
Imagine now we do this 1,000 more times and encounter the question again:
What is the capital of France?
It will probably have adjusted to see that it does not need a full word, and when it repeats the input it gets a better score. It may say “Fra” That is much closer than we have ever been. The loss is even lower now. It may have learned the entire pattern now and only say “F” That is 100% correct.
Upon reaching the end of the dataset, the model can look at all of the data rows again, for as many times as you ask it to (above we simulated looking at all the data 3 times). Eventually it will learn that a better score corresponds with repeating only the first letter of the input that does not match “What is the capital of “ and only matches the changing word “France”.
It is important that the model not look at the dataset too many times, because it may memorize the data and think the only countries it will ever be asked the capital letters for are in the dataset. So if it sees Moldova it may have memorized the answer is M, but have no idea how to derive that answer. Even worse would be when given the new word Mordor, the model has absolutely no idea how to answer because it has never seen the word before. In technical terms, such memorization is called overfitting.
